Sensitivity Rank in Data Classification
May 27, 2020
Data Discovery & Classification is supported for SQL Server 2012 and later, and can be used with SQL Server Management Studio (SSMS) 17.5 or later. Starting SSMS 18.5, a new feature called ‘sensitivity rank’ was added in Data Classification. I will show details about the sensitivity rank in this blog post.
I want to thank David Trigano, Program Manager – Microsoft Cybersecurity Engineering team for providing some of the information presented in this blog post.
Starting SSMS 18.5, when you classify data of any database, every classified column will get assigned a ‘sensitivity rank’.
The primary purpose of Rank is to provide built-in identification of the sensitivity level uniformly across every organization no matter what are the names of their labels used for classification (can be different because of the industry or the language, for example).
There are five possible values for sensitivity rank. Once you classify the data, you can see the details of columns using system catalog view sys.sensitivity_classifications .
| Rank | Rank Description |
|---|---|
| 0 | NONE |
| 10 | LOW |
| 20 | MEDIUM |
| 30 | HIGH |
| 40 | CRITICAL |
Following TSQL (copied from here) returns a table listing details for each classified column in the database, including ‘sensitivity rank’ details.
SELECT
SCHEMA_NAME(sys.all_objects.schema_id) as SchemaName,
sys.all_objects.name AS [TableName],
sys.all_columns.name As [ColumnName],
[Label],
[Label_ID],
[Information_Type],
[Information_Type_ID],
[Rank],
[Rank_Desc]
FROM
sys.sensitivity_classifications
left join sys.all_objects on sys.sensitivity_classifications.major_id = sys.all_objects.object_id
left join sys.all_columns on sys.sensitivity_classifications.major_id = sys.all_columns.object_id
and sys.sensitivity_classifications.minor_id = sys.all_columns.column_id
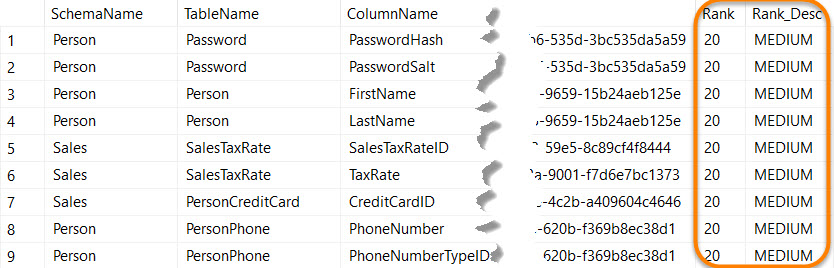
Going forward, when you add your sensitivity classification to one or more database columns, rank can be included by using a predefined set of values mentioned above. See ADD SENSITIVITY CLASSIFICATION for details.
Sensitivity rank information is not included in the report for three reasons:
- The first one is for backward compatibility.
- The second one is because this information is mainly used internally for other capabilities such as Auditing and SQL Advanced Threat Protection (ATP).
- The last one, which is linked to the second, is that the primary goal of the report is to be shared across the organization, and designers believe that the label name is enough to get a pretty good understand of what is the level of sensitivity of this label.












